Live streaming over the internet is an increasingly popular supplement to traditional broadcasting. With ever increasing demands regarding fast and scalable streaming, the widely adopted HTTP Live Streaming (HLS) standard has undergone recent (draft) revisions to enable lower end-to-end latencies. This version of the standard is commonly referred to as Apple Low-Latency HLS (LLHLS). It is different from previous efforts to supplement the “old” HLS standard with low-latency capabilities, commonly referred to as “Community Low-Latency HLS” (LHLS).
Simply put, Community LHLS advertises the most recent (edge) media segment to the receiver while it is still being produced, whereas Apple LLHLS advertises only those portions of it which are already available. Both approaches have their own upsides and downsides. Most prominently, Community LHLS breaks Adaptive Bit Rate (ABR) streaming due to chunked transfer and is already phased out in most implementations in favor of Apple LLHLS. The latter, however, makes caching through Content Delivery Network (CDNs) very hard due to very frequent and potentially client-dependent playlist updates.
While the choice of HLS flavour seems to boil down to the technical, logistical and practical pros and cons, it does not appear to be a question of delay – low latency is low latency after all, or is it not? Perhaps surprisingly, the practical delay bounds for each HLS flavour are not the same and their relative impact on end-to-end delay is larger than one might think. Let us investigate.
End-to-end delay comprises of many different factors, only some of which the sender (operating the live streaming source) can influence directly. Even the most creative engineers have very limited means against, for example, the transmission delay itself – the speed of light is quite a tough barrier to break in our Universe. However, accepting the physical limits of our Universe and thus our global network connections as they come, the remaining delay that can be influenced directly is worth analysing.
To explore the limits of HLS in terms of (influenceable) delay, engineers at NativeWaves set up a streaming server, a distribution (caching) server and a client (player) in a local network. The setup depicted in the image below is based on typical real-world setups for live events: The server captures a known Serial Digital Interface (SDI) input signal with a capture card, encodes it in hardware (on a Graphics Processing Unit (GPU)) and sends the encoded data via HLS directly to a distribution server which streams it to the client. Standard software (including FFmpeg with nvenc support) and typical settings (e.g., six seconds segment size) are used to make the results representative and as close as possible to practice.

The end-to-end delay is measured – from the time of capture at the streaming server to the earliest possible playback time at the client in the same local network. The measurements are analysed statistically, but instead of reporting the mean or median delay values, the 95th percentiles are presented. Reasoning about the worst-case delay that 95 per cent of users encounter portrays practical latency experiences much more accurately than focusing only on the better “half” of experiences.
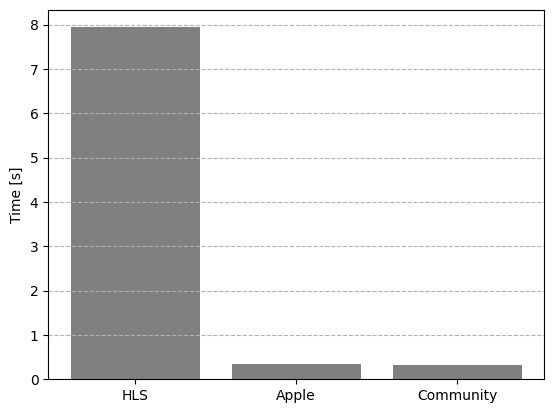
So, what do the results look like? The image on the right shows a comparison of the measured delay values for classical (non-low-latency) HLS (left), Apple LLHLS (middle) and Community LHLS (right). As expected, classical HLS produces orders of magnitude higher delay than the two low-latency flavours. The latter are nearly indistinguishable at this scale, but their differences will be broken down in more detail later. First, let us find out what causes the big difference between classical HLS and the two low-latency flavours.
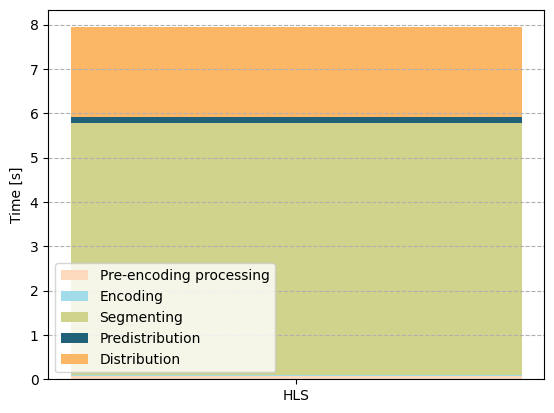
Breaking down the delay into its individual parts sheds some light onto the root cause of the high delay in classical HLS. As can be seen in the image to the left, all other parts become negligible when compared to segmenting (shown in green), i.e., the time required for splitting the content into segments.
Why is that? Since classical HLS requires producing a full segment before announcing it in the playlist, this means that, in the worst case, nearly one full segment worth of delay (6 seconds) is added on the production side when waiting for the segment to complete. The two low-latency flavours do not suffer from this as they allow for processing parts of segments as described above. So how do they compare?
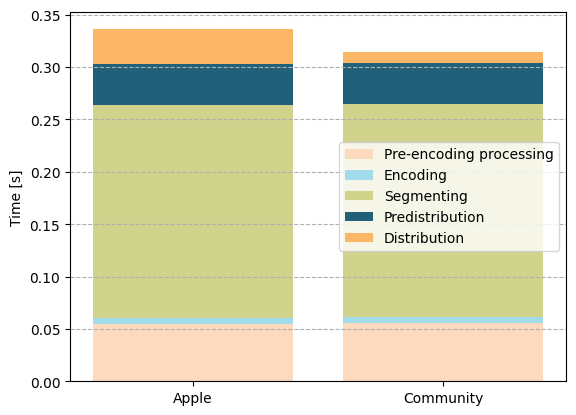
The image above breaks down the measured delays for Apple LLHLS and the Community HLS into their individual parts for comparison. Compared to classical HLS, the segmenting delay (shown in green) is drastically lower. In both low-latency HLS flavours, encoded data can be processed on a per-part (Apple LLHLS) or per-chunk basis (Community LHLS), where each part/chunk is only a fraction of the segment size, e.g., 0.2 seconds. This reduces the time spent waiting for a usable part of encoded data from the length of a segment to the length of a part/chunk and improves the overall delay compared to classical HLS dramatically.
However, there are still differences between the two low-latency HLS flavours. While both have the same delay caused by pre-encoding processing (e.g., buffering on the capture card, data conversion and transfer to the GPU), encoding (on the GPU) and segmenting, as discussed above, there are significant differences in the distribution-related parts. Both distribution-related delays are different because of the same reason: chunked transfer. While the transmission time from the segmenter to the caching server (pre-distribution) and from the caching server to the player (distribution) is limited by the line speed and the limits of the underlying communication protocols, Community LHLS benefits from sending the data while it is still being produced (chunked transfer), whereas Apple LLHLS does not allow this. This seemingly small difference has a significant effect on the overall delay.
While the overall delay of both low-latency HLS flavours is similar, Community LHLS is about 6 per cent (0.022 s) faster than Apple LLHLS in total. Some might question why such a difference is even relevant in practice, let alone why it is worth diving into the technical details of different low-latency HLS flavours. Are 0.33 s of delay not so low that any further optimisation efforts would be a waste of time? Beware: As described above, this analysis aims at exploring the limits of what different low-latency HLS flavours can achieve by making deliberately optimistic assumptions about the transmission delay to the client and by disregarding the buffer sizes that even low-latency-optimised players must use so that the video stream does not stutter during playback from the live edge. A smoothly playing client in a production-grade configuration of the NativeWaves setup would realistically experience an end-to-end delay of about 1 s. However, it is worth investigating how much impact the HLS flavours themselves have on the delay, especially when one (Community LHLS) can be pushed further than the other (Apple LLHLS).
To take this to the extreme, the chunk duration used in Community LHLS can even be reduced to one frame or 0.04 s in the described setup. As shown below, this reduces the segmenting delay nearly proportionally and reduces the overall delay of Community LHLS compared to Apple LLHLS to about 60 per cent (0.2 s), allowing Community LHLS to reach an overall delay of 0.13 s. All of this is possible without changes to the playlist as Community LHLS does not signal chunks explicitly. Conversely, Apple LLHLS would require signaling every part or frame in the playlist, which would increase the number of requests from the player enormously and make it practically infeasible. Due to this limitation, the image below uses 0.2 s parts for Apple LLHLS to allow for a fair comparison to the maxed-out Community LHLS with the smallest possible distribution delays that HLS with chunked transfer can realistically achieve.
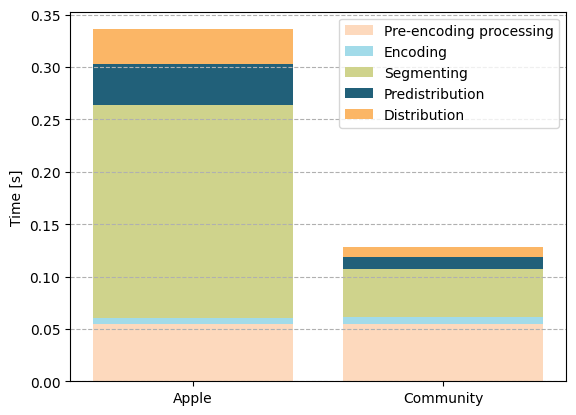
So, if Community LHLS is so much better in terms of delay, why is it being abandoned? As discussed, Community LHLS breaks ABR, and this is a big deal on the client side. When content from the edge is played and data is received via chunked transfer, the actual download speed cannot be measured reliably anymore, making ABR practically impossible. In addition, the standard has moved on to become Apple LLHLS and unofficial, community-driven efforts are a support risk that is not taken lightly by most technology providers.
What will the future of low-delay streaming bring? The short answer is Apple LLHLS. While being inferior in terms of the overall delay that can be achieved compared to Community LHLS, Apple LLHLS keeps ABR intact. Maybe someone somewhere will find a way to combine the advantages of chunked transfer from Community LHLS with the ABR capabilities of Apple LLHLS. Such a combination would truly minimise the delay for low-latency applications and make a very nice revision of the current (draft) low-latency HLS standard.






